Virtualbox虛擬主機網路設定 << Previous Next >> 圖形簡化
Virtualbox虛擬主機網路設定 << Previous Next >> 圖形簡化
換行code 改寫
圖中寫到 : 因html中可能還有中文字元在尚未喘成unf8時會出現語法錯誤 , 所以轉成unf8換完行後再轉回原本的字元
如右邊所呈現有成功換行
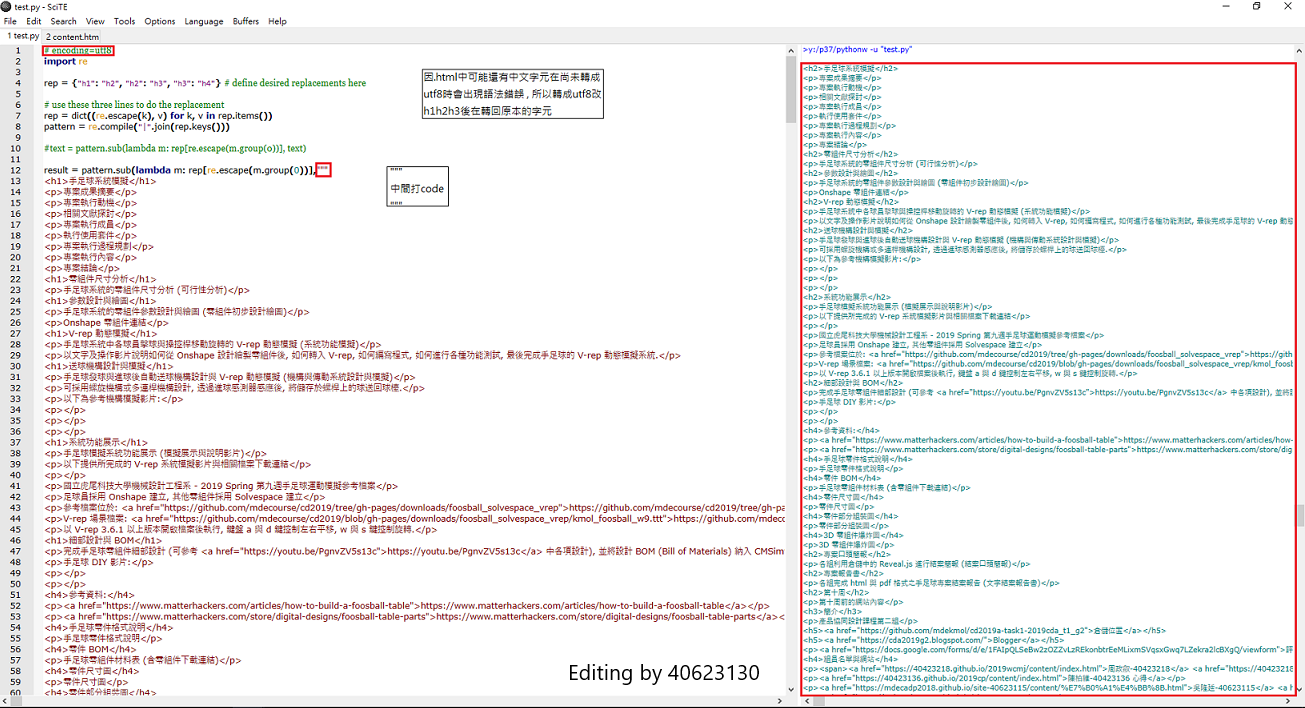
code:
# encoding=utf8
import re
rep = {"h1": "h2", "h2": "h3", "h3": "h4"} # define desired replacements here
# use these three lines to do the replacement
rep = dict((re.escape(k), v) for k, v in rep.items())
pattern = re.compile("|".join(rep.keys()))
#text = pattern.sub(lambda m: rep[re.escape(m.group(0))], text),editing by 40623130
result = pattern.sub(lambda m: rep[re.escape(m.group(0))],"""
""")
print(result)
Virtualbox虛擬主機網路設定 << Previous Next >> 圖形簡化